

About 100 Days of AI:
I am Nataraj, I decided to spend 100 days in starting Jan 1st 2024 to learn about AI. With 100 days of AI is my goal to learn more about AI specifically LLMs and share ideas, experiments, opinions, trends & learnings through my blog posts. You can follow along the journey here.
If you have been following the generative AI or the LLM space you would have already heard about Finetuning. In this post lets try to understand what finetuning is and what is its role in developing gen AI applications.
What is Finetuning?
Finetuning is a process of modifying a general purpose base model to make it work for a specialized use case. For example take gpt-3 model by Open AI. Gpt-3 is a base model which was finetuned for the purpose of being a chat bot which resulted in what people now refer to as chat-gpt application. Another example would be modifying GPT-4 model to be a copilot for coders, which was done to create GitHub co-pilot.
Why do we have to finetune the base models?
Finetuning allows us to overcome the limitation of base models. Base models like Open AI’s gpt-3 or Meta’s Llama are usually trained on the entire internet’s data. But they do not have the context of the data that is internal to your organization. And giving all the data that is relevant to your organization or proprietary use case via prompt is not possible. Finetuning allows us to fit in a lot more data than prompt engineering allows us. Finetuning also allows the model to generate consistent outputs, reduce hallucinations & customize the model for a particular use case.
How is finetuning different from prompt engineering?
We have seen how powerful prompt engineering can be in the previous posts. So how is finetuning different? Finetuning is for enterprise applications use case while prompt engineering is for general use cases and doesn’t require data. It can be used with additional data with RAG as a technique but it cannot be used with large data that exists in enterprise use cases. Finetuning allows for unlimited data, makes the model learn new information, it can also be used along with a RAG.

Comparing Finetuned vs Non-Finetuned response
Lets take an example that might give you a better intuition of the difference between finetuned vs non-finetuned models. I am using lamini‘s libraries to call both finetuned and non-finetuned Llama models to show the difference. You will need the api key from Lamini for this purpose. Lamini provides a simple and easy way to interact with open source LLMs. Check it out here if you want to learn more about it.

In this example I have asked both the models the same question “What do you think of death?” and here are the reponses.
Response from Non-Finetuned Llama Model:

Response from Finetuned Llama Model:

You will notice that the first response was just repetition of a single line, while second response much more coherent response. Before talking about what is happening here lets take another example where I ask the model “What is your first name?”. Here’s what I got.
Response from Non-Finetuned Llama Model:
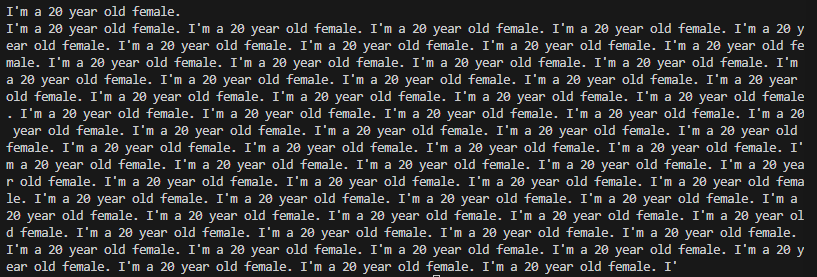
Response from Finetuned Llama Model:
In non-finetuned model responses, the responses are weird because the model is just doing one thing. It is trying to predict the next probable text based on your input text, it is not also realizing that you posed it a question. Based models which are trained on the internet’s data are text predicting machines and try to predict the next best text. With finetuning the model is trained to base its response by giving additional data and it learns new behavior that is to act as a chat bot meant to answer questions. Also note that most of the closed models like Open AI’s gpt-3 or gpt-4 we do not exactly know what data they are trained on. But there are some cool open data sets out there which can be used to train your models. More on that later.
That’s it for Day 11 of 100 Days of AI.
I write a newsletter called Above Average where I talk about the second order insights behind everything that is happening in big tech. If you are in tech and don’t want to be average, subscribe to it.
Follow me on Twitter, LinkedIn for latest updates on 100 days of AI. If you are in tech you might be interested in joining my community of tech professionals here.